
Turning big data into manageable incidents
In my last blog post, I spoke about Formula 1 cars and how they are big data systems. Many gigabytes of data are collected from sensors on a car, used for both real time decisions during a race and for offline analysis. So, If F1 cars are big data collectors, my car is just a small data collector, right? There’s an odometer, speedometer, rev counter and a few lights that tell me if something is going catastrophically wrong.
That amount of data is just about manageable for me. It’s all on a single dashboard that I can see and understand at a single glance. But when you are collecting gigabytes of data, thousands of data points per second for hundreds of different streams of telemetry, it’s a different story.
And like in F1, the scale of the data we collect from the network can go way beyond what we can fully make sense of from a single glance. If you’re responsible for any wireless, switching, or WAN environments, you’ve probably experienced this for yourself. There are too many things to look at - graphs, changing patterns or trends, and alerts.
One solution to this problem is automation. That’s why we have developed an AI system to programmatically identify unusual behaviour and issues within your network, in real time. We call this system Incident Detection.
When it comes to data processing, heuristics and static thresholding and visual inspection will take you to a certain point. But beyond that point, the number of things you measure becomes too large and disparate for this. The problem is that a specific threshold or heuristic that is appropriate to one subset of your data just isn’t appropriate for a different subset. These are not characteristics you can entirely anticipate.
A solution is to build a system for identifying unusual behaviour that is based on the data itself. This is why we use AI. Such a system can account for differences across subsets of the data dynamically, programmatically responding to changes over time without the need for manual tuning.
Because you cannot just buy ready-made algorithms for use within network scenarios, we build customized models, specific to your network’s characteristics. We also ensure that you always have up-to-date models, so we retrain weekly and use robust methods to ensure that our automated retraining is reliable. The constant measuring and tuning improve our systems which allows us and you to be more responsive to problems.
AI-powered Incident Detection helps you maximise the value of the measurements we capture on a consistent basis. This system becomes the eyes you need to continuously track your users’ experience, surface significantly unusual incidents as they are happening, and optimise your time. We are adding AIOps to our solution so that you don’t have to keep your eyes glued to a dashboard and comb through alert on top of alert. Without AI/ML there’s no way to remain efficient as your business or organization goes forward.
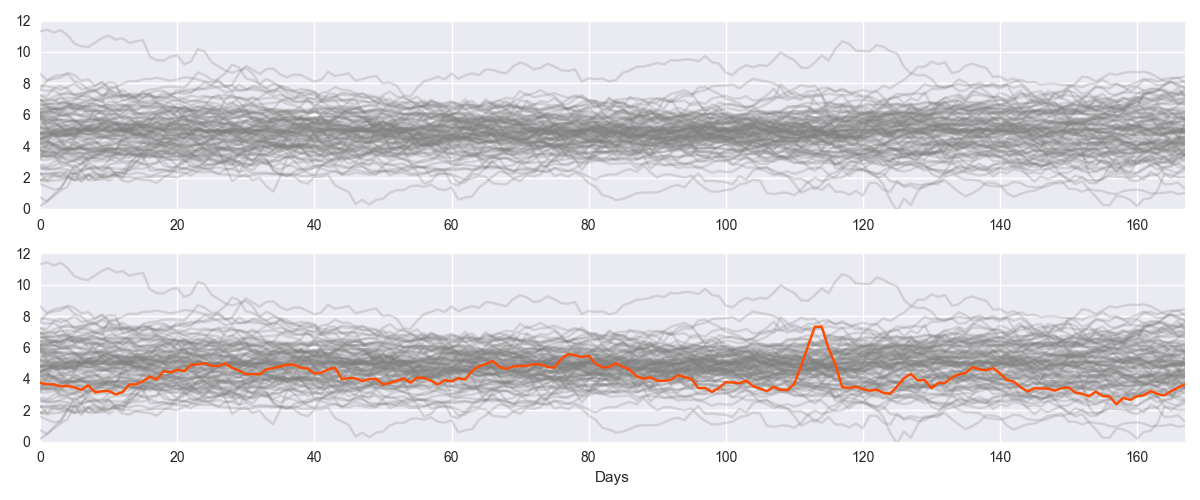 Image A: Detecting abnormalities across disparate data sets. When you see the orange line in the bottom panel of Image A, it highlights an obvious period of abnormality. But in the top panel, where it is grey like the other lines, you don't pick up the abnormal period. When you are making many measurements with different behaviour, it’s very difficult to manually define thresholds for detecting abnormal behavior. A better way is to look for anomalies programmatically, dynamically comparing sets of measurements to their own past behaviour.
Image A: Detecting abnormalities across disparate data sets. When you see the orange line in the bottom panel of Image A, it highlights an obvious period of abnormality. But in the top panel, where it is grey like the other lines, you don't pick up the abnormal period. When you are making many measurements with different behaviour, it’s very difficult to manually define thresholds for detecting abnormal behavior. A better way is to look for anomalies programmatically, dynamically comparing sets of measurements to their own past behaviour.
Let me know if you’d like to better understand how the models work and I’ll go deeper in another blog.



